AI PH Mixer


Find the Atmel touchscreen device:
$ xinput --list
⎡ Virtual core pointer id=2 [master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4 [slave pointer (2)]
⎜ ↳ FocalTechPS/2 FocalTech FocalTech Touchpad id=17 [slave pointer (2)]
⎜ ↳ Logitech USB Optical Mouse id=20 [slave pointer (2)]
⎜ ↳ Atmel id=10 [slave pointer (2)]
⎣ Virtual core keyboard id=3 [master keyboard (2)]
↳ Virtual core XTEST keyboard id=5 [slave keyboard (3)]
↳ Power Button id=6 [slave keyboard (3)]
↳ Sleep Button id=9 [slave keyboard (3)]
↳ USB2.0 UVC HD Webcam id=13 [slave keyboard (3)]
↳ Video Bus id=7 [slave keyboard (3)]
↳ AT Translated Set 2 keyboard id=16 [slave keyboard (3)]
↳ Video Bus id=8 [slave keyboard (3)]
↳ Asus WMI hotkeys id=15 [slave keyboard (3)]
The Atmel device is our touchscreen.
Use the xinput disable and enable commands to turn the touchscreen off or on again.:
$ xinput disable Atmel $ xinput enable Atmel
Both commands are silent, unless you specify a device that doesn't exist.
It is easy to create EC2 keypairs with the AWS CLI:
$ aws ec2 create-key-pair --key-name mynewkeypair > keystuff.json
After creating the keypair it should appear in your EC2 key pairs listing. The
keystuff.json file will contain the RSA private key you will need to use
to connect to any instances you create with the keypair, as well as the name of
the key and its fingerprint.
{ "KeyMaterial": "-----BEGIN RSA PRIVATE KEY-----\n<your private key>==\n-----END RSA PRIVATE KEY-----", "KeyName": "mynewkeypair", "KeyFingerprint": "53:47:ee:01:3a:35:9b:52:1c:4f:99:6f:87:b0:0f:8b:ed:83:55:3b" }
To extract the private key into a separate file, use the jq JSON filter.
$ jq '.KeyMaterial' keystuff.json --raw > mynewkey.pem
If you're using GitLab.com for hosting your repositories, you may have encountered a strange problem wherein your newly-created repository's dashboard doesn't update.

That is, when you git push your changes to the repository, the interface still looks like a newly-created repository, and neither your files nor your commits are visible in the web UI. This is weird because the remote repository works in all other respects. You can push code up to it, clone it, etc. You just can't see it on the GitLab website.
I've seen this happen a couple of times, and so far I've found that the quick fix is to run Housekeeping on the repository from the Edit Project page.

Housekeeping can take a couple of minutes but most of the time it works and you can see your repository's files and commit history after running it. If it doesn't work, you have to delete the repository in GitLab and re-create it, pushing your code up again.
CentOS 7 ships with python 2.7.5 by default. We have some software that requires 2.7.11. It's generally a bad idea to clobber your system python, since other system-supplied software may rely on it being a particular version.
Our strategy for running 2.7.11 alongside the system python is to build it from source, then create virtualenvs that will run our software.
# as root yum upgrade -y yum groupinstall 'Development Tools' -y yum install zlib-devel openssl-devel
# As a regular user (avoid doing mundane things as root) $ cd /tmp $ wget https://www.python.org/ftp/python/2.7.11/Python-2.7.11.tgz $ tar -zxf Python-2.7.11.tgz $ cd Python-2.7.11
/opt (replace with /usr/local/ if you prefer)$ ./configure --prefix=/opt/ $ make $ make install

I've been writing a lot of Python code recently. Oftentimes I struggle with what a method should return when I have to relay more than one value back to the caller. For example:
def PaymentGateway: def do_transaction(self, target, amount, bill_code, **kwargs): """ Perform some transaction against the API. :return: whether the transaction was successful or not :rtype: bool """ # stuff happens here try: result = self.amount_transaction(tx_details) logger.info("Success: CODE=%s Details=%s" % (result.code, result.detail)) return True except GatewayException as ex: logger.error("Transaction failed: ERROR=%s reason=%s" % (ex.err_code, ex.message)) return False
The code that calls do_transaction might look like this:
if payment_gw.do_transaction(subid, amount, bill_code, service_id, ref_code) is True: # Hooray! Succe$$! report_success("Transaction for %s was successful. Check logs for status code." % subid) else: # Boo report_failure("Transaction failed. I don't know why...")
Many times this is fine, but what if the caller needs the details from the amount_transaction result or the GatewayException? A quick solution is to return a dict :
def PaymentGateway: def do_transaction(self, target, amount, bill_code, **kwargs): """ Perform some transaction against the API. :return: a dict that contains keys 'success', 'code', and 'detail' :rtype: dict """ # stuff happens here try: result = self.amount_transaction(tx_details) logger.info("Success: CODE=%s Details=%s" % (result.code, result.detail)) success_dict = { 'success': True, 'code': result.code, 'detail': result.detail, } return success_dict except GatewayException as ex: logger.error("Transaction failed: ERROR=%s reason=%s" % (ex.err_code, ex.message)) error_dict = { 'success': False, 'code': ex.err_code, 'detail': ex.message, } return error_dict
It works but it's pretty ad-hoc. The structure of whatever do_transaction returns won't be obvious unless you dig into the code. The caller will end up like:
payment_status = payment_gw.do_transaction(subid, amount, bill_code, service_id, ref_code) if payment_status['success'] is True: # Hooray! Succe$$! report_success("Transaction for %s was successful, status code %s" % (subid, payment_status['code'])) else: # Boo report_failure("Transaction failed, because: %s" % payment_status['detail'])
Now the caller is poluted with literal strings like 'success', 'code' and 'status'. These can be hell to debug, specially if you happen to misspell one of them in your code. Even if you're using an awesome IDE like PyCharm.
An altenative to defining these ad-hoc dict structures is to use namedtuple from the collections package.
from collections import namedtuple PaymentStatus = namedtuple('PaymentStatus', ['success', 'code', 'detail']) def PaymentGateway: def do_transaction(self, target, amount, bill_code, **kwargs): """ Perform some transaction against the API. :return: whether the transaction was successful or not :rtype: PaymentStatus """ # stuff happens here try: result = self.amount_transaction(tx_details) logger.info("Success: CODE=%s Details=%s" % (result.code, result.detail)) return PaymentStatus(True, result.code, result.detail) except GatewayException as ex: logger.error("Transaction failed: ERROR=%s reason=%s" % (ex.err_code, ex.message)) return PaymentStatus(False, ex.err_code, ex.message)
namedtuple forces us to be explicit about what do_transaction returns. And explicit is better than implicit. For the caller, this looks like:
payment_status = payment_gw.do_transaction(subid, amount, bill_code, service_id, ref_code) if payment_status.success is True: # Hooray! Succe$$! report_success("Transaction for %s was successful, status code %s" % (subid, payment_status.code)) else: # Boo report_failure("Transaction failed, because: %s" % payment_status.detail)
This is almost as simple as our first example, and is free of string literals. And if you're using PyCharm, you can take advantage of the code completion which will know about the attributes of your new namedtuple class:
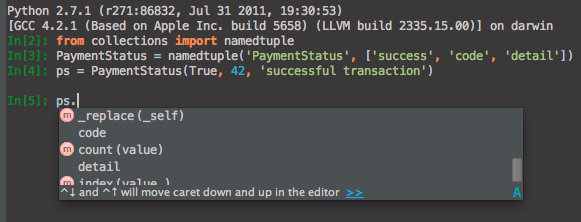
So if your code is littered with string literals as keys for return values from methods that return dict, consider having them return a namedtuple instead.
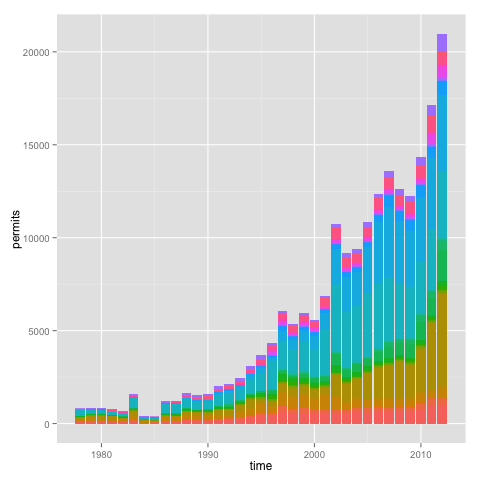
The Bureau of Local Employment issues working permits to foreign nationals that want to work in the Philippines. Ever wondered which nationalities obtain the most permits? I used public data from the BLE in a data cleanup and visualization exercise using R’s reshape, dplyr and ggplot2.

I will admit, I was pretty stoked yesterday when Roger Peng retweeted my announcement that his new book was available.
. @rdpeng's new book "The Art of Data Science" is now available on @leanpub. Get it at https://t.co/nA606G715i #datascience
— Brian Baquiran (@brianbaquiran) November 24, 2015
In the book, Peng and co-author Elizabeth Matsui walk us through the different activites of data analysis, from formulating questions, basic exploratory data analysis to get a rough feel for the data, to modelling the data with familiar distributions through to basic inference and prediction.
Using R and the datasets that come bundled with it, Peng and Matsui demonstrate how each activity is actually an iterative process itself. At each stage, it's important to evaluate what you already know (or think you know) and revise your expectations based on the data.